Writing a translator in a day, with Dhaka
Jun. 15th, 2009 12:21 pmI suppose you could generously call this a compiler, but it's so simple that I won't even try to make that case.
For a project I'm working on, I need the ability to write queries. I have objects (files) with tags, and each tag has an optional value associated with it. So, I want to be able to write something like this:
This would return all the files with the tag "unheard" (any value, or none), and with the "bitrate" tag (either value 192, or value 'variable').
I was originally going to hack something stupid together, but I figured, it's a lazy Sunday, I was eventually going to have to rewrite any hacked-up crap I did by hand anyway, and maybe whatever Ruby has wouldn't be as horrible as when I did this in 2006 with lex and yacc.
Oh man, was I right. The best parser generator I found for Ruby, Dhaka, was vastly easier than lex/yacc, and I liked using it so much that I think I want to write this post just to go through the process again.
Making a translator with Dhaka
Writing a translator like this has three steps: first you need a thing to recognize individual tokens in the language, then you need a thing to understand sentences made out of tokens, then you need a thing to actually do what those sentences say.
In a natural language like English:
The Lexer
Which is short for "Lexical analyzer". Dhaka makes lexers by reading in a class called a "LexerSpecification". Here's mine:
You make a lexer specification by calling
The way this works is, it scans the input, trying to match to one of those patterns. When it finds it, it runs the block associated with the pattern, which (usually) creates a token and returns it (sometimes it will do stuff to it beforehand, like my string token that un-escapes quotes).
So, we have turned the text of our query into a stream of tokens. Now we need to assemble these into a parse tree.
The Parser
This section is going to be a little bit longer, because what this does is a little more complex.
Just like the lexer assembled letters into a sequence of tokens, the parser assembles tokens into a tree. And, in Dhaka, it works mostly the same way: I make a class that specifies how the parser should work, and then I make a parser out of it.
You would expect this class to be called a "ParserSpecification", mirroring the "LexerSpecification", but it's actually called a "Grammar". Here's mine:
You can read this grammar like this:
When you start, look for a "Query".
A "Query" is either:
1. Another "Query", then an "and" token, then a "Query", in which case it's an "intersection" Query, or
2. Another "Query", then an "or" token, then a "Query", in which case it's a "union" Query, or
3. Just a "Clause" by itself, in which case we call it a "oneclause" Query
4. A "(" token, then a Query, then a ")" token, in which case it's a "parenthesized_query" Query
A "Clause" is either:
1. A "symbol" token, then an "=" token, then a "Value", in which case it's an "equality" Clause
...and so on...
At each step, the grammar just defines what different sentences look like, and gives them names. Note that some of the definitions (Query especially) use themselves in the definition, this is what enables us to pile as many Clauses as we want in a Query.
So using this grammar, Dhaka can make a program that recognizes things. If we want to (and we do), we can make Dhaka print out pictures of how it handles certain things:
This will make a file that a tool called GraphViz can read, and draw this diagram from:

Just one last thing to explain about this grammar: that bit up top called "precedence".
Let's say you have a query like this: "a or b and c". Does that mean "has a, or has both b and c" or does it mean "has either a or b, and has c"? With parentheses: "a or (b and c)" or "(a or b) and c"? This simple distinction is what parse trees are meant to iron out.
I've decided, basically arbitrarily, that I want that query to mean the former ("has a, or has both b and c"). In computer-science-speak, I want the "and" operator to have a higher precedence than the "or" operator. So, that block is where (and how) I tell Dhaka that, and the parser that it generates handles the rest.
And you can see from the diagram that it does: it's parsed as a union query with the right side being an intersection query, rather than as an intersection query with the left side being a union query.
The Evaluator
Compared to the parser, this is downright simple. All we're going to do is take the nodes in the parse tree that Dhaka builds for us and generate the right Ruby code for them.
A little bit about what I want to build:
I have a big heap of files, remember, and I want to sift through them. What I'd like to do is have something that I can pass a string to ("a or b and c") and get back a Proc that I can run on a file:
So, I want to generate a little bit of code for each kind of sentence in the grammar. The "start" sentence would generate the "Proc.new" part, then whatever its child is, then "end". The "intersection" sentence would generate whatever its left child is, then "and", then whatever its right child is. And so on.
Here's part of the evaluator I have:
"emit" is just a function that builds up a big string. At the end, I eval the string, and I have my Proc!
Strings
Well, almost. One last bit.
I decided that dealing with strings, quoting and escaping and such in the generator, was too much of a pain. So, the for_string handler is a little strange:
I store all the literal strings in a big table that I call "strings". I generate the Proc inside a function that has this table as a local variable, so it gets stuck in the Proc's closure.
Tying it all together
I just need to write a little function that will use the generator to make a Proc, like so:
Then I can run it on all my files:
And finished!
So, what does Dhaka do better than lex/yacc?
First off, it's all Ruby. No weird code generation step, no different file formats, it just slots neatly into your program.
Second, because it's Ruby, you don't need to care about malloc or free. Doing anything in C is a huge pain because of this, and parsers are even worse because you're trying to build a large structure (the parse tree) across function calls.
But the main benefit is that it builds the parse tree for you, and even draws a diagram of it. That's like a whole step that you don't have to deal with, and another step that becomes so much easier to debug.
For a project I'm working on, I need the ability to write queries. I have objects (files) with tags, and each tag has an optional value associated with it. So, I want to be able to write something like this:
unheard and (bitrate=192 or bitrate='variable')This would return all the files with the tag "unheard" (any value, or none), and with the "bitrate" tag (either value 192, or value 'variable').
I was originally going to hack something stupid together, but I figured, it's a lazy Sunday, I was eventually going to have to rewrite any hacked-up crap I did by hand anyway, and maybe whatever Ruby has wouldn't be as horrible as when I did this in 2006 with lex and yacc.
Oh man, was I right. The best parser generator I found for Ruby, Dhaka, was vastly easier than lex/yacc, and I liked using it so much that I think I want to write this post just to go through the process again.
Making a translator with Dhaka
Writing a translator like this has three steps: first you need a thing to recognize individual tokens in the language, then you need a thing to understand sentences made out of tokens, then you need a thing to actually do what those sentences say.
In a natural language like English:
- The tokens would be things like: "a word is any sequence of characters bounded on either side by whitespace or punctuation", or "punctuation is any of these symbols: ' " ; , : . ? ! ( )".
- The sentence-recognizer would be like: "a noun is any of these words: bear, tree, water", and "a sentence is a noun phrase, then a predicate" and "a noun phrase is a noun, or an adjective followed by a noun".
- Finally, the thing that carries out sentences is just a person, who understands English.
- The tokens are the symbols "=", "and", "or", "(", ")", any number, any quoted text (like "this is a string"), any unquoted single words (like bitrate).
- The sentence recognizer assembles those tokens into a "parse tree".
- Finally, another thing called the "evaluator" does what the query says, by translating the parse tree into Ruby code that does the same thing (and then running the Ruby code).
The Lexer
Which is short for "Lexical analyzer". Dhaka makes lexers by reading in a class called a "LexerSpecification". Here's mine:
class QueryLexerSpecification < Dhaka::LexerSpecification
operators = {
'(' => '\(',
')' => '\)',
'=' => '=',
'and' => 'and',
'or' => 'or'
}
operators.each do |operator, regex|
for_pattern(regex) do
create_token(operator)
end
end
for_pattern('-?\d+(\.\d+)?') do
create_token('number')
end
for_pattern(/'([^\\']|\\[\\'])*'/) do
raw=current_lexeme.value
escaped=raw.gsub('\\\'','\'').gsub('\\\\','\\')
dequoted=escaped[1..(escaped.length-2)]
create_token('string',dequoted)
end
for_pattern(/[a-zA-Z0-9_\-]+/) do
create_token('symbol')
end
for_pattern('\s+') do
# ignore whitespace
end
end
QueryLexer = Dhaka::Lexer.new(QueryLexerSpecification)
You make a lexer specification by calling
for_pattern a lot, with regular expressions that match the token. For example, the block up there that calls create_token('number') matches things like "-9.32", or "4". This lexer can be run on a string and will output a stream of tokens:QueryLexer.lex(str).each do |token| puts token.symbol_name+"\t"+token.value end
The way this works is, it scans the input, trying to match to one of those patterns. When it finds it, it runs the block associated with the pattern, which (usually) creates a token and returns it (sometimes it will do stuff to it beforehand, like my string token that un-escapes quotes).
So, we have turned the text of our query into a stream of tokens. Now we need to assemble these into a parse tree.
The Parser
This section is going to be a little bit longer, because what this does is a little more complex.
Just like the lexer assembled letters into a sequence of tokens, the parser assembles tokens into a tree. And, in Dhaka, it works mostly the same way: I make a class that specifies how the parser should work, and then I make a parser out of it.
You would expect this class to be called a "ParserSpecification", mirroring the "LexerSpecification", but it's actually called a "Grammar". Here's mine:
class QueryGrammar < Dhaka::Grammar
precedences do
left ['or']
left ['and']
end
for_symbol(Dhaka::START_SYMBOL_NAME) do
start %w| Query |
end
for_symbol('Query') do
intersection %w| Query and Query |
union %w| Query or Query |
oneclause %w| Clause |
parenthesized_query %w| ( Query ) |
end
for_symbol('Clause') do
equality %w| symbol = Value |
presence %w| symbol |
end
for_symbol('Value') do
string %w| string |
number %w| number |
end
end
QueryParser = Dhaka::Parser.new(QueryGrammar)
You can read this grammar like this:
When you start, look for a "Query".
A "Query" is either:
1. Another "Query", then an "and" token, then a "Query", in which case it's an "intersection" Query, or
2. Another "Query", then an "or" token, then a "Query", in which case it's a "union" Query, or
3. Just a "Clause" by itself, in which case we call it a "oneclause" Query
4. A "(" token, then a Query, then a ")" token, in which case it's a "parenthesized_query" Query
A "Clause" is either:
1. A "symbol" token, then an "=" token, then a "Value", in which case it's an "equality" Clause
...and so on...
At each step, the grammar just defines what different sentences look like, and gives them names. Note that some of the definitions (Query especially) use themselves in the definition, this is what enables us to pile as many Clauses as we want in a Query.
So using this grammar, Dhaka can make a program that recognizes things. If we want to (and we do), we can make Dhaka print out pictures of how it handles certain things:
File.open('parse.dot', 'w') do |file|
file << QueryParser.parse(QueryLexer.lex("a or b and c")).to_dot
end
This will make a file that a tool called GraphViz can read, and draw this diagram from:
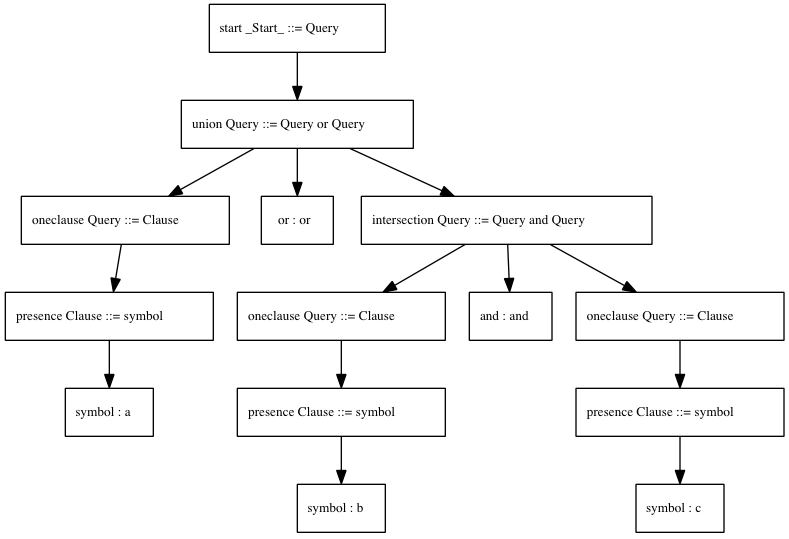
Just one last thing to explain about this grammar: that bit up top called "precedence".
Let's say you have a query like this: "a or b and c". Does that mean "has a, or has both b and c" or does it mean "has either a or b, and has c"? With parentheses: "a or (b and c)" or "(a or b) and c"? This simple distinction is what parse trees are meant to iron out.
I've decided, basically arbitrarily, that I want that query to mean the former ("has a, or has both b and c"). In computer-science-speak, I want the "and" operator to have a higher precedence than the "or" operator. So, that block is where (and how) I tell Dhaka that, and the parser that it generates handles the rest.
And you can see from the diagram that it does: it's parsed as a union query with the right side being an intersection query, rather than as an intersection query with the left side being a union query.
The Evaluator
Compared to the parser, this is downright simple. All we're going to do is take the nodes in the parse tree that Dhaka builds for us and generate the right Ruby code for them.
A little bit about what I want to build:
I have a big heap of files, remember, and I want to sift through them. What I'd like to do is have something that I can pass a string to ("a or b and c") and get back a Proc that I can run on a file:
Proc.new do |file|
file.has_tag?('a') or file.has_tag?('b') and file.has_tag?('c')
end
So, I want to generate a little bit of code for each kind of sentence in the grammar. The "start" sentence would generate the "Proc.new" part, then whatever its child is, then "end". The "intersection" sentence would generate whatever its left child is, then "and", then whatever its right child is. And so on.
Here's part of the evaluator I have:
class QueryEvaluator < Dhaka::Evaluator
self.grammar=QueryGrammar
define_evaluation_rules do
for_start do
emit "Proc.new{|file|"
evaluate child_nodes[0]
emit "}"
end
for_intersection do
evaluate child_nodes[0]
emit "and"
evaluate child_nodes[2]
end
for_number do
child_nodes[0].token.value
end
for_presence do
sym=child_nodes[0].token.value
emit "file.has_tag?('#{sym}')"
end
### ...Several handlers skipped...
end
end
"emit" is just a function that builds up a big string. At the end, I eval the string, and I have my Proc!
Strings
Well, almost. One last bit.
I decided that dealing with strings, quoting and escaping and such in the generator, was too much of a pain. So, the for_string handler is a little strange:
for_string do
idx=add_string child_nodes[0].token.value
"strings[#{idx}]"
end
I store all the literal strings in a big table that I call "strings". I generate the Proc inside a function that has this table as a local variable, so it gets stuck in the Proc's closure.
Tying it all together
I just need to write a little function that will use the generator to make a Proc, like so:
def evaluate_query str tree = QueryParser.parse(QueryLexer.lex(str)) evaluator = QueryEvaluator.new evaluator.evaluate(tree) strings = evaluator.strings eval(evaluator.function_text) end
Then I can run it on all my files:
query = evaluate_query("a or b and c")
Files.all.delete_if{|file| !query.call(file) }
And finished!
So, what does Dhaka do better than lex/yacc?
First off, it's all Ruby. No weird code generation step, no different file formats, it just slots neatly into your program.
Second, because it's Ruby, you don't need to care about malloc or free. Doing anything in C is a huge pain because of this, and parsers are even worse because you're trying to build a large structure (the parse tree) across function calls.
But the main benefit is that it builds the parse tree for you, and even draws a diagram of it. That's like a whole step that you don't have to deal with, and another step that becomes so much easier to debug.